0.原则
- 解决大量重复性工作:办公多半是基于Windows系统,应用程序大多为office三件套、网页OA系统、
- 例如工作常用的惯用操作、可复用的鼠标点击—鼠标移动—保存信息操作、新建文档和文件。
- 准备计算机基础知识:不需要很多软件工程的知识,但需要基本的数据结构、流程控制、I/O文件系统、网络通信的知识。
- 数据结构:list、set、map、string
- 流程控制:迭代、循环、条件、枚举
- 文件系统:txt文件解析、html、Excel文件解析、PDF文件解析、
- 进阶:浏览器插件、JavaScript拦截修改
- 网络通信:网络层IP、应用层http、邮件服务器SMTP+pop3、浏览器开发者工具
- 善用GPT:GPT在工程领域的应用缺陷还十分明显,但在自动化办公方面的帮助是显而易见的。
- 一是自动化办公需求分散,代码分散,而GPT擅长的就是单次、信息量有限的代码prompt。
- 二是虽然GPT生成代码效率之高,但在实际解释运行时往往会出现各种问题。除了可以反复进行需求描述强化来迭代出最符合需求的代码之外,再加之python语言的极简化,直接对生成代码进行修改和可读性都是相当之高的。
- 明确边界:尽管这部分IT技术适用于一些文员的办公处理,但不适用于一些存在专业知识的领域进行信息处理。他们更应该采用专业的工业软件。
- 例如以下几个行业职位:会计、出纳、金融、设计、视频剪辑
- 相应的工业软件:
- 会计-SAP、
- UI-即时、Sketch、figma、axure
- 海报-ps、其他付费SaSS平台
- 视频:ae、pr
一、文本处理
1.格式化
- 正则:字符串匹配、分割、检验
二、爬虫
1.库的使用和特点
- requests:经典的发送http请求的库
- bs4:dom树的解析
- 应用:requests+bs4能处理大部分静态渲染页面的数据请求,
- 缺点:但无法处理JavaScript动态渲染的数据。所以下面我会介绍使用一些进阶的浏览器自动化测试工具,它们很好支持与JavaScript联动。这里推荐一个浏览器插件:Wappalyzer,它支持快捷的查看一个网站使用的前端技术栈,以及是否是SSR(静态渲染)。
- Scrapy:一个整合的异步爬虫框架
- 工程化:说白了就是request+bs4的封装对象化版本,性能更高而已。
- 安装:pip install scrapy
- 创建:scrapy startproject myproject
- 编辑:cd myproject—scrapy genspider example example.com—— 编写代码
myproject/spiders/example.py -
import scrapy class ExampleSpider(scrapy.Spider): name = 'example' start_urls = ['http://www.example.com'] def parse(self, response): # 提取网页标题 title = response.css('title::text').get() # 提取网页链接 links = response.css('a::attr(href)').getall() yield { 'title': title, 'links': links } - 运行:scrapy crawl example
- 建议:详情可看教程Scrapy | A Fast and Powerful Scraping and Web Crawling Framework,但并不适合新手,因为没必要。
- 工程化:说白了就是request+bs4的封装对象化版本,性能更高而已。
- Selenium:著名的自动化测试框架,模仿浏览器行为
- 教程:入门指南 | Selenium
- 安装:安装python库——选择驱动——引入开发
- 事件模拟:action = ActionChains(driver)
- 应用:自动翻页、自动登录
- Prerender:一个基于node.js的服务端渲染JavaScript的技术。
- 教程:Prerender(JavaScript 网站静态化) - 知乎 (zhihu.com)
- 应用:听说可以执行JavaScript,但还是有点麻烦就懒得弄了。
2.小平台
- 免费图库:
- 堆糖:曾经想试手但能力有限,虽然人家是个小厂但也是有技术人员的。我预料本不好扒,具体可以参考很多小说网站起点文学、笔趣阁,它们的html代码可以说日新月异,更不要说一旦前后端分离导致的seo都失效了,爬虫更是难以存活。
- 英雄联盟英雄图库:b站有教程,基本流程就是从js代码中扒到参数加密过程——扒到请求地址——伪造请求头——请求到数据并整理保存。
3.主流平台
- 特点:
- 爬虫策略:伪造header,特别是User-agent头信息,并且要尝试带有cookie信息。
- 动态页面:像b站、twitter这类主流网站都统一采用了vue等框架,直接爬只能爬到JavaScript代码,无法获取想要的数据。
- 应对策略
- 1.分析网络请求:使用开发者工具观察页面加载时发送的网络请求,有时页面的数据可能是以 JSON 格式在后台加载的。你可以模拟发送相同的请求来获取数据。
- 2.手动测试:直接控制台查看dom结构,复制下来进行半自动解析。
- 实例:b站爬某个up的主页视频数据。
- 这里我采用的是第二种方法,需要自己手动粘贴html代码,好处是简单,适用于去批量下载某些up的视频。
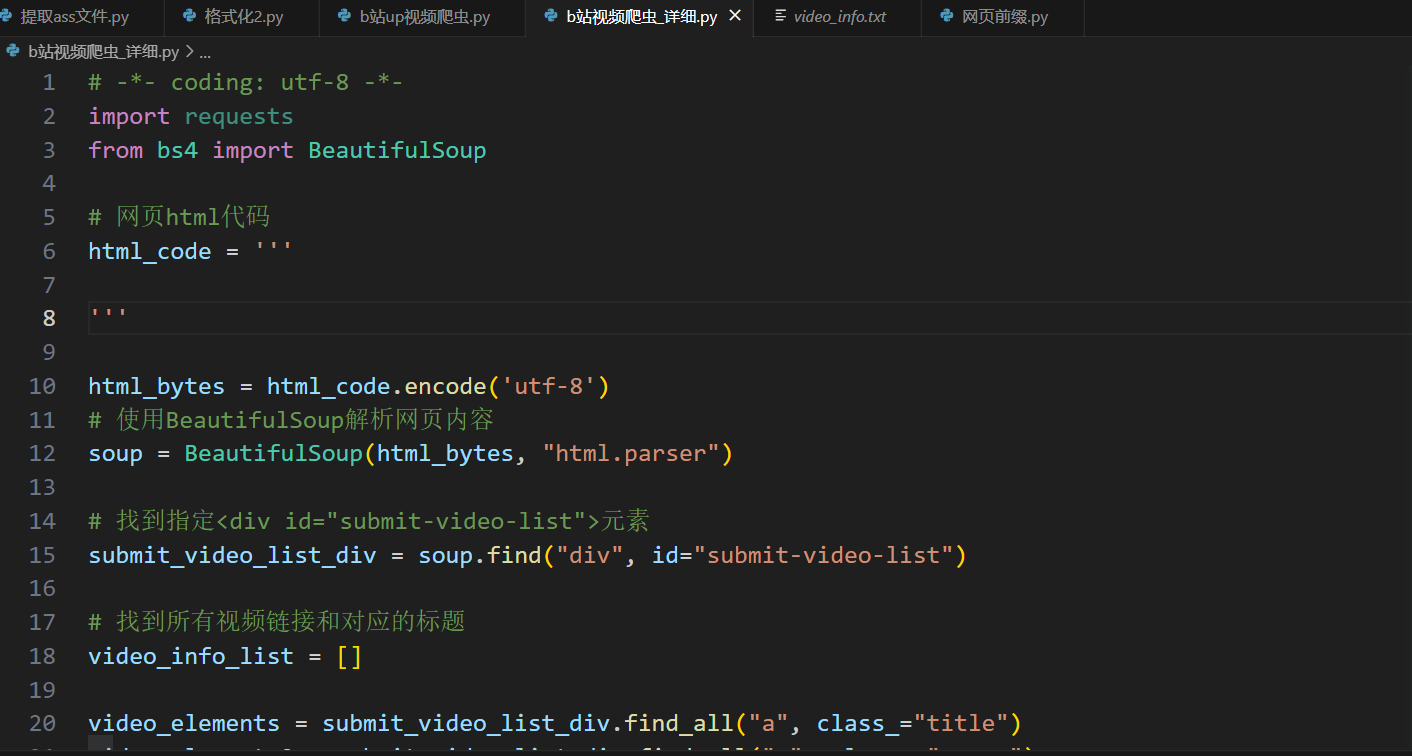
- 百度网盘:广搜链接并按关键字查找,实例参考悟空链接
- 原理:不知道它们的数据来源,但你会发现它们的信息很有限,很多低价值的垃圾信息。
- 应用:这些链接的信息熵巨大,很难也根本不值得去分类,只能靠用户去靠关键字检索。总结来说,除了建站毫无用处。
- 磁力链接:同上
- 原理:p2p磁力链接的价值日益底下,这是毋庸置疑的。因为任何信息都有其商业价值和版权问题、技术进步带来的媒体公司和内容提供商的变革,它们为用户提供更便捷的方式来获取和共享任意垂直领域的内容。即web2.0给大家带来了高质量的流媒体体验。
- 现实:p2p的资源节点基本已经被迅雷公司所垄断,尽管如此他的发展情况可见一斑的差。
- 在线文档:很危险!会收律师函的,有老哥先例的。推荐别去做。
- 百度文库:待研究。
4.公司OA系统
- 前言:这块我没有过多涉及,也想不出有哪些需要自动化操作的场景,OA的场景一般是待处理工单、IM通信、在线会议,和人打交道的事还是尽量自己完成把。
- 小公司OA产品:前后端未分离的后端渲染技术产品。
- 权限:OA产品的数据权限是严格限制的,爬虫只是高效的帮助你获取能手动收集到的数据信息。它并不生产数据也不可能绕开服务器的权限验证。
- 泛微:未使用过。
- 微软teams:双端应用,据我所知微软授权费很贵,所以没有多少公司在用。
- 清内存:因为即时通信会占用大量的存储空间,而当某些公司会可以限制员工办公电脑的硬盘大小(比如我的实习公司),所以推荐使用edge浏览器。
三、excel处理
1.互转
- 前言:其实实测下来网络平台更稳定,转换支持的格式也更全更多
- word转pdf:直接调用库python-docx、docx
- Excel转pdf:直接调用库openpyxl
下面是GPT生成的,实际使用效果是可以的。
from docx import Document
import pdfplumber
import openpyxl
from PyPDF2 import PdfReader, PdfWriter
def word_to_pdf(input_path, output_path):
doc = Document(input_path)
pdf = output_path + '.pdf'
doc.save(pdf)
def pdf_to_word(input_path, output_path):
pdf = PdfReader(input_path)
text = '\n'.join([page.extract_text() for page in pdf.pages])
doc = Document()
doc.add_paragraph(text)
doc.save(output_path + '.docx')
def excel_to_pdf(input_path, output_path):
wb = openpyxl.load_workbook(input_path)
ws = wb.active
pdf = output_path + '.pdf'
ws.title = 'Sheet1'
wb.save(input_path)
wb.close()
# 输入文件路径和输出文件路径
input_file = 'input_file_path'
output_file = 'output_file_path'
# 调用相应的函数进行文件转换
word_to_pdf(input_file, output_file)
pdf_to_word(input_file, output_file)
excel_to_pdf(input_file, output_file)
2.操作
- 前言:我并不是很理解有人会有这部分需求,但可能他们真的存在,也许就是文员,要做一些数据录入导出。但这些使用代码级的高级语言api来操作的任务应该是由OA系统或采购系统的it设计和开发人员来完成的。如果有条件,直接反馈给领导让公司it部门去实现需求,公司养他们就是干这种事的。强烈不建议自己去学习并写自动化脚本来完成一些个性化但重复的工作,编写-修改bug-反复迭代代码是一件浪费精力和时间的事,除非你真的喜欢做这种编码的感觉(我觉得并不可能)。
- 数据处理:
- 推荐库:Openpyxl 教程|极客教程 (geek-docs.com)和 Pandas 教程 | 菜鸟教程 (runoob.com)
- openpyxl:简单的增删改查和函数计算都支持,推荐使用。
- Pandas:比较火热的数据分析库,是基于著名运算库numpy进一步封装的库。比较臃肿和复杂,不推荐使用。
四.操作系统
1.Windows运维
- 硬件问题:
- 蓝屏:我在打英雄联盟时蓝屏了无数次,原因无外乎是内存溢出了,进程滥用内存和数量是限制我的最大原因(钱)。每次蓝屏后Windows会在c盘系统路径 C:\Windows\Minidump留下日志文件,但这个文件需要微软专门工具去查看。但其实它也只会告诉你导致系统崩溃的进程是哪个,需要你自己去排查。所以省点力把。
- wifi网卡问题:更改无线协议,具体参考win10 连接个别WiFi就瞬间蓝屏重启 - Microsoft Community
- 鼠标:故障率低,FPS无脑GPW系列,非FPS游戏玩家推100雷蛇或罗技G102.
- 键盘:故障率中,我用过三把机械键盘,有一把无线的确实问题很多,最主要问题就是触线按折了导致按键失灵。
- 办公:无脑樱桃红轴(ikbc),耐用第一位。
- 出差:笔记本键盘顶用。 有条件者上罗技,毕竟无线技术之神。
- 打游戏、下班后学习:常备青轴(阿米洛海韵)。
- sc config i8042prt start= disabled 禁用
- sc config i8042prt start= auto 开启键盘
- 硬盘:信息传输效率要求是很高的
- 丢失数据:这个曾经还真遇到过,不过是在u盘上,一般的国产商业软件都要付费。推荐PowerDataRecovery数据恢复 7.0黄金版。
- 存片:移动硬盘成本低,但实际使用体验不如云盘和网站。关键问题还是在信息的传输效率!
- 耳机:故障率高
- 无线耳机:400起步,无脑大厂旗舰。
- 有线耳机:开黑必备,隐私性有保障。
- 显卡:故障率中
- 选购原则:无脑60系列,不买矿、不二手。
- 售后服务:很重要,现在很多cpu不带核显,这玩意有一出问题电脑就报废。
- 声卡和麦克风:闲置率高,普通人完完全全不需要,耳机麦即可(连姿态、水晶哥都是耳机麦)。
- 只推荐:淘宝小奶瓶
- 使用群体:特殊职业者
- 蓝屏:我在打英雄联盟时蓝屏了无数次,原因无外乎是内存溢出了,进程滥用内存和数量是限制我的最大原因(钱)。每次蓝屏后Windows会在c盘系统路径 C:\Windows\Minidump留下日志文件,但这个文件需要微软专门工具去查看。但其实它也只会告诉你导致系统崩溃的进程是哪个,需要你自己去排查。所以省点力把。
- 网络问题:
- ip地址:有时路由器的DHCP服务器会动态分配ip失败,尤其是当频繁切换WIFI时。此时一般手动设置网络ip、网关、子网掩码即可。
- 代理:这里涉及到计算机网络知识较多了,简而言之,现代的本地代理服务器软件如shadowrocket、v2ray已经相当支持可视化去设置相关网络配置了。有想深入了解的建议问GPT。
- 外挂逆向:何为逆向?正向就是开发,反之逆向就是研究别人的开发成功,反向进行一些修改,达成一些开发者预料之外某部分用户的需求。但这类技能并不能成为工作,也并不会在面试中被提问。总之往黑客发展是不受大众和国家认可的。只能做自媒体——参考这位老哥镖客熊猫江的个人空间_哔哩哔哩_bilibili
- 内存挂:CE是一个手动检测并修改小型应用程序或游戏内存数据的好工具;DBG可以调试一个进程做绕过一些license验证的工作。
- 适用范围:小型单机、大型单机
- 与TP对抗:lol换肤、lol脚本、cf大哥
- 自动外挂开发:网游外挂需要与时俱进这是肯定的,相当于你在和另一帮有逆向技术的老哥在做博弈,人家有钱拿回家陪老婆孩子你呢?单机或小众游戏外挂稳定但门槛低同款实现会很多,基本赚不了钱(除非与2233这种流氓厂家合作)。
- 视觉挂:CV物体检测,python简单运行脚本即可实现。
- 适用范围:FPS的爆头检测,但根本无游戏性可言,非常不推荐!依旧躲不开封号系统,例如cf的460机制。
- 内存挂:CE是一个手动检测并修改小型应用程序或游戏内存数据的好工具;DBG可以调试一个进程做绕过一些license验证的工作。
五.总结
如有读者耐心看完我这篇文章,会发现python好像也就那么回事,在软件开发工程化、云原生化的今天,它并不适合用来构建一些高性能、高可用、高可维护性的软件系统。他更多的被使用于编程入门、信息处理入门、机器学习入门、优雅的做LeetCode题。后续我再使用python的话,大概率就会是一些OpenCV机器视觉算法的学习使用了。所以,本篇到此为止了!
创作于2023/08/23.
本文作者为抱一只橘,转载请注明。